
今回は、「Stable Diffusion web UI」をWindowsやMacにインストールする方法と、その使い方を紹介します。
Stable Diffusion web UIについて
Stable Diffusion web UIは、ブラウザをインターフェースとして利用して、AIによる画像生成を行うことができるツールです。
GitHub[AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
Stable Diffusion web UIでは、次のような画面をブラウザで動かすことができ、かんたんにAIによる画像生成を行うことができます。
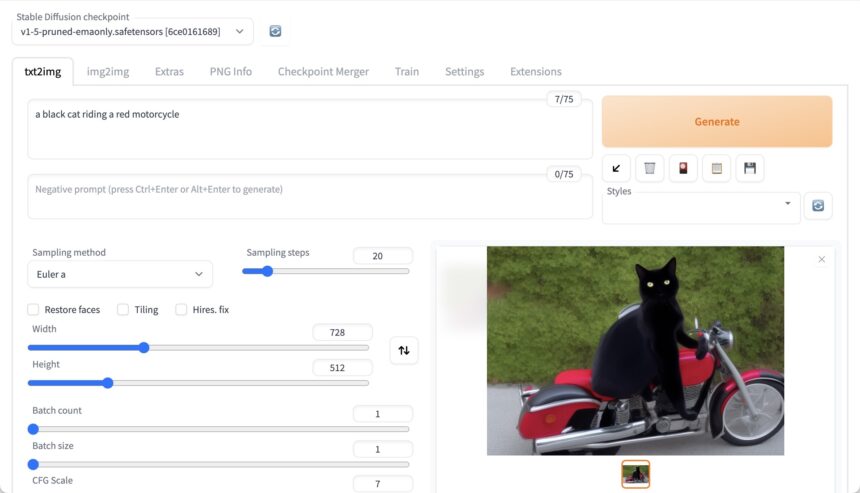
この、ブラウザを使うというスタイルのおかげで、Windowsでも、Mac(Apple Silicon)でも、Linuxでも動かすことができます。
さらにはGoogle Colabなどで環境を整え、高速のGPUを使って動かすこともできますし、ここでは解説しないのですが、家にあるハイスペックなPCで起動しておき、ローカルサーバを立てて、同じネットワークの別のPC、Mac、スマホなどから、ブラウザでアクセスして使うこともできます。
柔軟な使い方ができ、GUIによる操作で分かりやすいので、私としては、画像生成AIに「Stable Diffusion web UI」を使うことをおすすめしています。
インストール
では、実際に「Stable Diffusion Web UI」をインストールしてみましょう。
Windows
Windowsのローカル環境で「Stable Diffusion Web UI」を動かすために必要なものです。
- Python 3.10.6(https://www.python.org/downloads/release/python-3106/)
- Git(https://git-scm.com/)
- NVidia GPU(AMD GPUにも対応しているのですが、NVidia GPUを推奨しています)
まず、「Stable Diffusion Web UI」では、Python 3.10.6が必要になります。(2023/06/03現在)
また、Pythonのインストールのとき、「Add Python 3.10 to PATH」にチェックを入れる必要があります。
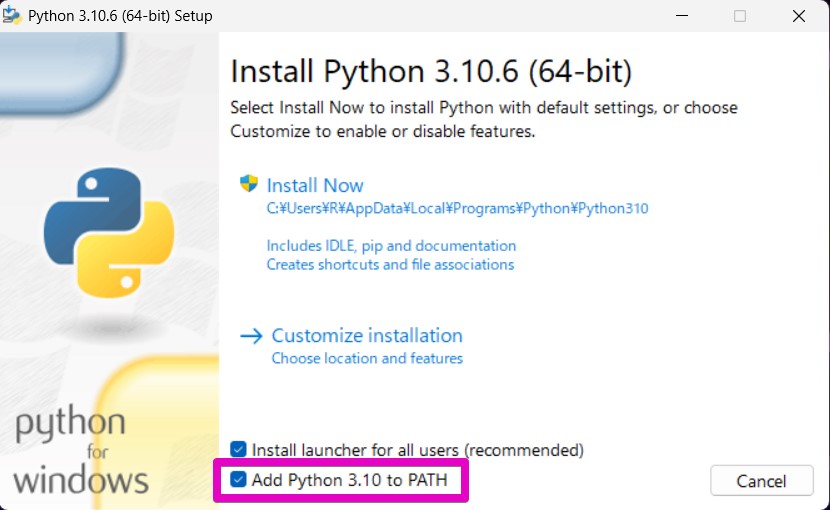
詳しい情報はGitHub[AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)をご覧ください。
では、Windowsに「Stable Diffusion Web UI」をインストールしていきましょう。
PowerShellを開き、cdコマンドで任意のディレクトリに移動したあと、以下のコマンドを一行ずつ順番に実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd .\stable-diffusion-webui\
.\webui-user.batとても時間がかかりますが、待ちましょう。
しばらくすると、「Running on local URL:」と表示されるので、その後ろのリンクを開きます。
もし、Pythonを他の目的でも使っている場合、バージョンを3.10.6に固定するのはむずかしいかもしれません。
そんなときはAnacondaなどを使うと便利になります。
Anaconda:https://www.anaconda.com/
Mac (Apple Silicon)
必要なツールのインストールに、Homebrewを使いますので、あらかじめインストールしておきましょう。
ターミナルを開き、cdコマンドで任意のディレクトリに移動したあと、以下のコマンドを一行ずつ順番に実行します。
brew install cmake protobuf rust python@3.10 git wget
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
./webui.shとても時間がかかりますが、待ちましょう。
しばらくすると、「Running on local URL:」と表示されるので、その後ろのリンクを開きます。
Google Colab
ローカルでAI画像生成を行おうとすると、やはりスペックの高いマシンが必要になります。
しかし、高額のマシンを購入するのは、なかなかできるものではありません。
そんなとき、Google Colabの力を借りることで、高性能のマシンを持っていなくても、「Stable Diffusion Web UI」を動かすことができます。
Google Colabで「Stable Diffusion Web UI」を使う方法は、こちらの記事で詳しく解説しておりますので、ご覧ください。
Stable Diffusion web UIの実行と終了
つづいて、ローカルでStable Diffusion web UIを動かすときの、実行と終了の方法です。
いろんな方法がありますが、インストールのときのコマンドでも実行できます。
(さきほどのインストールのときは時間がかかりましたが、今回、もうインストールは済んでいるので時間はかかりません)
Windows
Windowsの場合は、cdコマンドでstable-diffusion-webuiフォルダに移動したあと、webui-user.batを実行します。
cd stable-diffusion-webui
.\webui-user.batまた、stable-diffusion-webuiフォルダにあるwebui-user.batを、ダブルクリックで実行することもできます。
終了するには、control + cを押して、さらに質問にYと入力します。
Mac (Apple Silicon)
Windowsの場合は、cdコマンドでstable-diffusion-webuiフォルダに移動したあと、webui.shを実行します。
cd stable-diffusion-webui
./webui.shまた、control + cで終了できます。
かんたんな使い方
ここまでの内容で、Stable Diffusion Web UIを使うことができるようになったと思います。
ここからは、使い方を学んでいきましょう。
画像生成AIでは、どういうイラストを生成したいのかを、言葉や文によって伝えます。
この言葉や文のことを、「プロンプト(Prompt)」と呼びます。
プロンプト(Prompt)や、ネガティブプロンプト(Negative prompt)は、下の画像の場所に入力します。
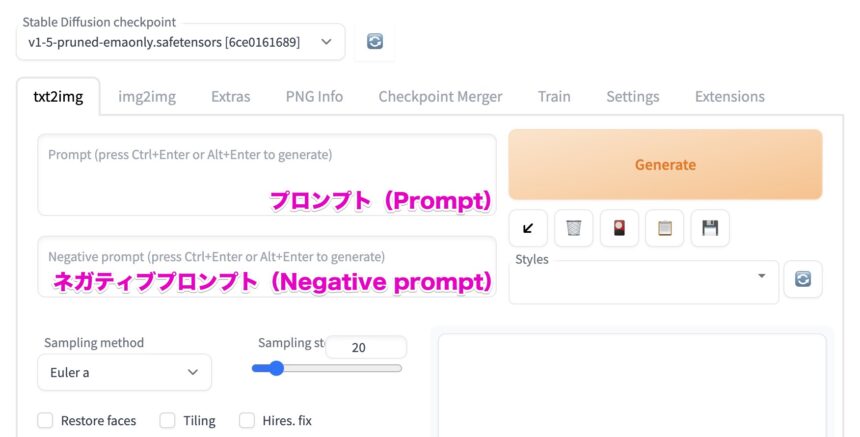
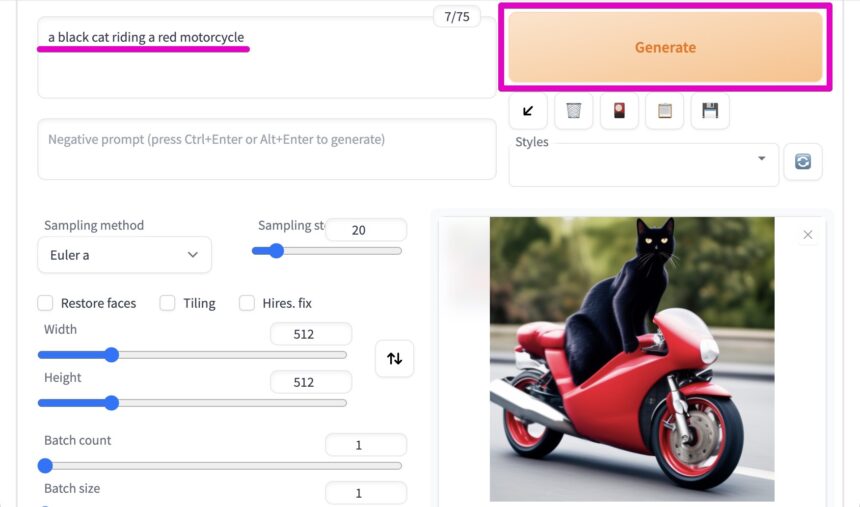
たとえば、「a black cat riding a red motorcycle(赤いオートバイに乗った黒猫)」とプロンプトを入力し、「Generate」をクリックします。
すると、下のような画像が生成されます。(基本的に、毎回違う画像が表示されます)
パラメータについて
つづいて、Stable Diffusion web UIで画像生成するための、パラメータを見ていきましょう。
各パラメータの値を変えることで、画像生成におけるいろんな設定をすることができます。
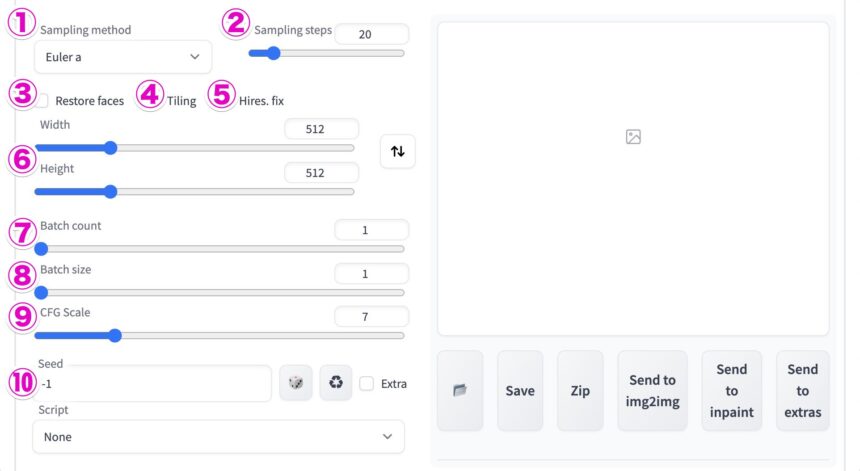
| 1. Sampling method | サンプリング方法 |
|---|---|
| 2. Sampling steps | ノイズからイラストに変えていくための回数 |
| 3. Restore faces | 顔を綺麗にできる(美人になるとは限らない) |
| 4. Tiling | タイル状に並べる |
| 5. Hires. fix | 解像度を上げることができる |
| 6. Width, Height | 画像の横幅、高さ |
| 7. Batch count | 画像の枚数(何回バッチを行うか) |
| 8. Batch size | 画像の枚数(1回のバッチで何枚の画像を生成するか) |
| 9.CFG Scale | どれだけプロンプトに近いイラストを生成するか |
| 10. Seed | Seedの数値と他の設定によって絵が決まる。-1にするとランダム |
Sampling steps
Sampling stepsは、ノイズをイラストに変えていくための回数です。
画像生成では、最初はノイズを作成し、そこから少しずつ、プロンプトに沿ったイラストにしていきます。
Stepsが多いほど鮮明になりますが、ある程度まで鮮明になれば、そこからは絵自体が変わっていきます。

Restore faces
「Restore faces」のチェックを入れることで、顔が綺麗になります。
ただ、美人になる、とは言えないかもしれません。

CFG Scale
CFG Scaleは、数値を高くするとプロンプトに近いイラストを生成することができます。
ただ、高くしすぎると、絵が崩れてしまうこともあります。

モデルについて
AI画像生成において、プロンプトやパラメータによる設定も重要なのですが、どのモデルを使うのかというのもとても大切です。
モデルとは、入力に対して、判断して、結果を出力する、という仕組みです。
さまざまなモデルがデータファイルとして配布されており、基本的には、自分の好みに合ったものを使います。
モデルが変わると、画風がまったく変わります。
モデルの形式は、safetensorsとckptがありますが、セキュリティの観点から、safetensorsの方が多く使われています。
モデルを探したい場合は、次の記事を参考にしてください。
モデルやVAEの配置と切り替え
では、モデルの切り替え方法を見ていきます。
まず、使いたいモデルを見つけたら、そのダウンロードページをよく読みます。
すると、よく必要なものが書かれている場合があり、そこにはVAEと書いてある場合があります。
モデルを切り替えるには、そのモデルファイルや、VAEを、決まったディレクトリに配置する必要があります。
ここではBasil Mixを例に、モデルの切り替え方法を見ていきましょう。
Basil Mixでは、VAEにvae-ft-mse-840000を使うことが推奨されています。
Hugging Face[nuigurumi/basil_mix]:https://huggingface.co/nuigurumi/basil_mix
VAE: vae-ft-mse-840000:https://huggingface.co/stabilityai/sd-vae-ft-mse-original
今回は、「Basil_mix_fixed.safetensors」、「vae-ft-mse-840000-ema-pruned.safetensors」のふたつのファイルを使います。
これらを以下の場所に配置しましょう。
stable-diffusion-webui/
|-- models/
| |-- Stable-diffusion/
| | `-- Basil_mix_fixed.safetensors
| |-- VAE/
| | `-- vae-ft-mse-840000-ema-pruned.safetensors
| `-- 〜省略〜
`-- 〜省略〜では、モデルを変更してみましょう。
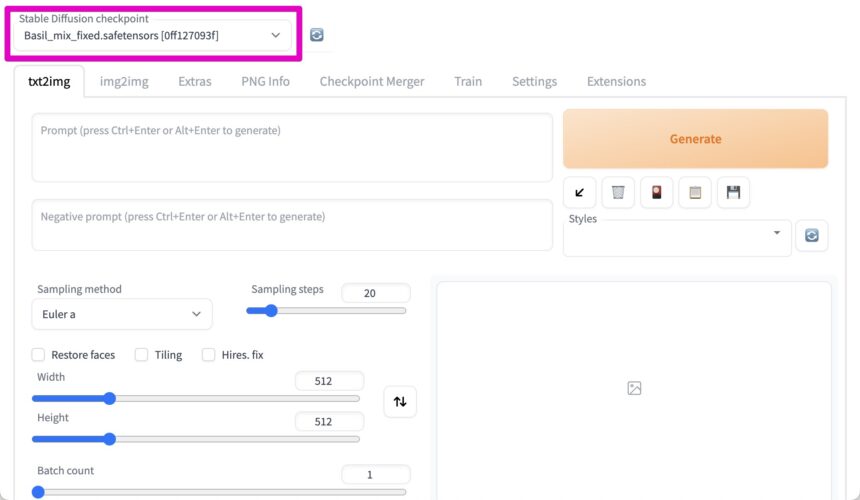
「Stable Diffusion checkpoint」のところで、モデルを変更することができます。
(もしうまく読み込まれていないようならば、右隣の再読み込みボタンをクリックします)
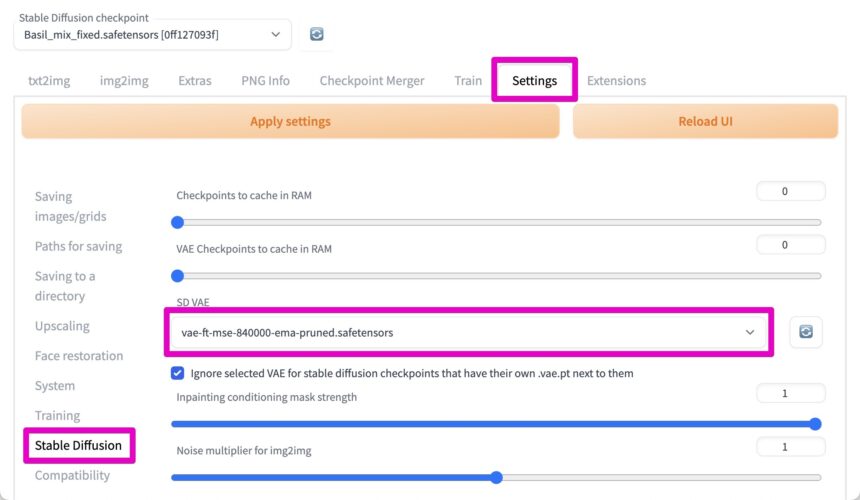
また、VAEも設定します。
Settingsから、Stable Diffusionと選択し、SDVAEの項目で、用意したVAEを選択します。
(もしうまく読み込まれていないようならば、右隣の再読み込みボタンをクリックします)
これで、モデルやVAEを切り替えることができます。
また、Colabを使ったBasil Mixでのイラスト生成の方法を知りたい方は、こちらの記事を参考にしてください。
まとめ
今回は、Stable Diffusion Web UIのインストール方法から、使い方までを紹介しました。
Stable Diffusion Web UIは、ブラウザをインターフェースとして使って、かんたんな操作でAI画像生成を行うことができるツールです。
Google Colabなどでも動かして操作ができ、多くの環境で使えるのも、Stable Diffusion Web UIのメリットのひとつです。









